Indexing
Posted on Apr 26 - 2025
Back up your life, one file at a time
Tech
Many people think that backing up their data is somewhat boring. True, but more tedious is the indexing of all the files on which the backup is applied.
It’s easy to create a folder and put all the photos and videos in it, but the name of each file, their metadata, and their structure is much harder to manage.
If you want to search for all the photos taken on a certain day, are you sure they are all displayed?
I don’t know why, but towards the end of the year, I always tend to want to finish something tedious but that brings correct and satisfying results for the new year. So this and next week will be dedicated to indexing progress and backup methods. I won’t go into too much detail but I will try to give an overview of how I have structured everything.
The first step was to define an indexing method that would allow me to find each file in a simple and fast way. For the scheme, I relied on Freeform.
The structure is of the type:
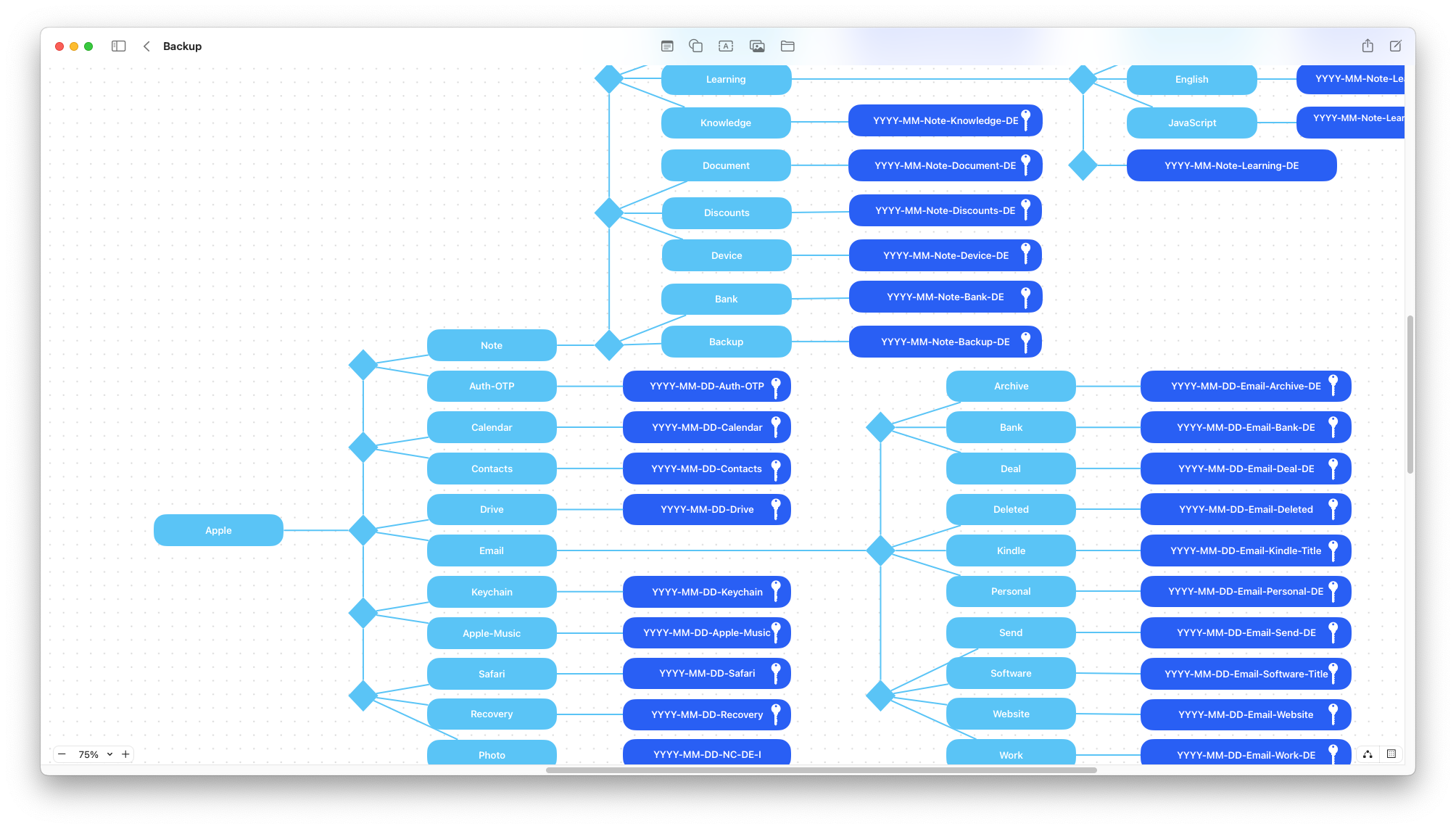
Where each file is defined on a set of four parameters:
Date
Allows you to focus on specific time ranges.Path
A concept similar to date but with a search you can get all the files in a certain folder.People
People are described with two letters that identify first and last name. So you can get all the files of a person or groups of people who are in the same file.Description
General description of the file.
The combination of these elements in a single file allows the simplest identification and search.
Be aware that there is a maximum character limit that a file can have. This value is defined by the operating system or rather by the file system. Most support a maximum of 256 characters (including file extension, for example .pdf).
In my case, I have set a limit of 200 characters. Any file that exceeds this limit is modified by making the description parameter smaller.
For convenience, I made a Python script that counts the number of characters of each file showing those that exceed 200 characters.
import os
def check_name_length(folder):
files = os.listdir(folder)
for file in files:
name_length = len(file)
if name_length > 200:
print(f"WARNING: Name length of '{file}' exceeds 200 characters!\n\n")
current_folder = os.getcwd()
check_name_length(current_folder)
On average, out of 5000 files, I had to rename from 2 to 4 files, so a completely acceptable number.
The next step is to copy the files to the disks intended for backup. By copy, I don’t mean a “copy and paste” but something more specific.
Once a file is copied from point A to point B, how can we be sure that the copy in B is exactly the same as that in A?
For many, the answer is to open the file and say “yes they are the same, the photos are the same, the document has the same lines, the video plays and so on”.
In reality, it’s not quite like that.
Let’s take these two images:

And:

At first glance, they are the same while in reality, they are two completely different images!
We can get this information from the checksum of the two images. The checksum is like the unique signature of each file, if the signatures are different then the files are different (as much as to the human eye the files may look the same).
In the first image the checksum is:
8f3c0d16d20684aa659242fc750860066bcacbdabf9d9f66032de1209d4c811e
The second:
f2ab45d2d1ce7168af13af63b58b1193791cb2a09d0bbe420bfd04021ffae2f9
They are completely different values. This difference is due to the fact that in the second image I modified a single pixel from a slightly white shade to completely white. Imperceptible to the human eye but that completely modified the “originality” of the file.
Therefore, to be sure that the copy is the same as the original, we need software or a script that checks the checksum of each copied file. In my case, I relied on Carbon Copy Cloner which allows you to verify the checksum of each copied file.
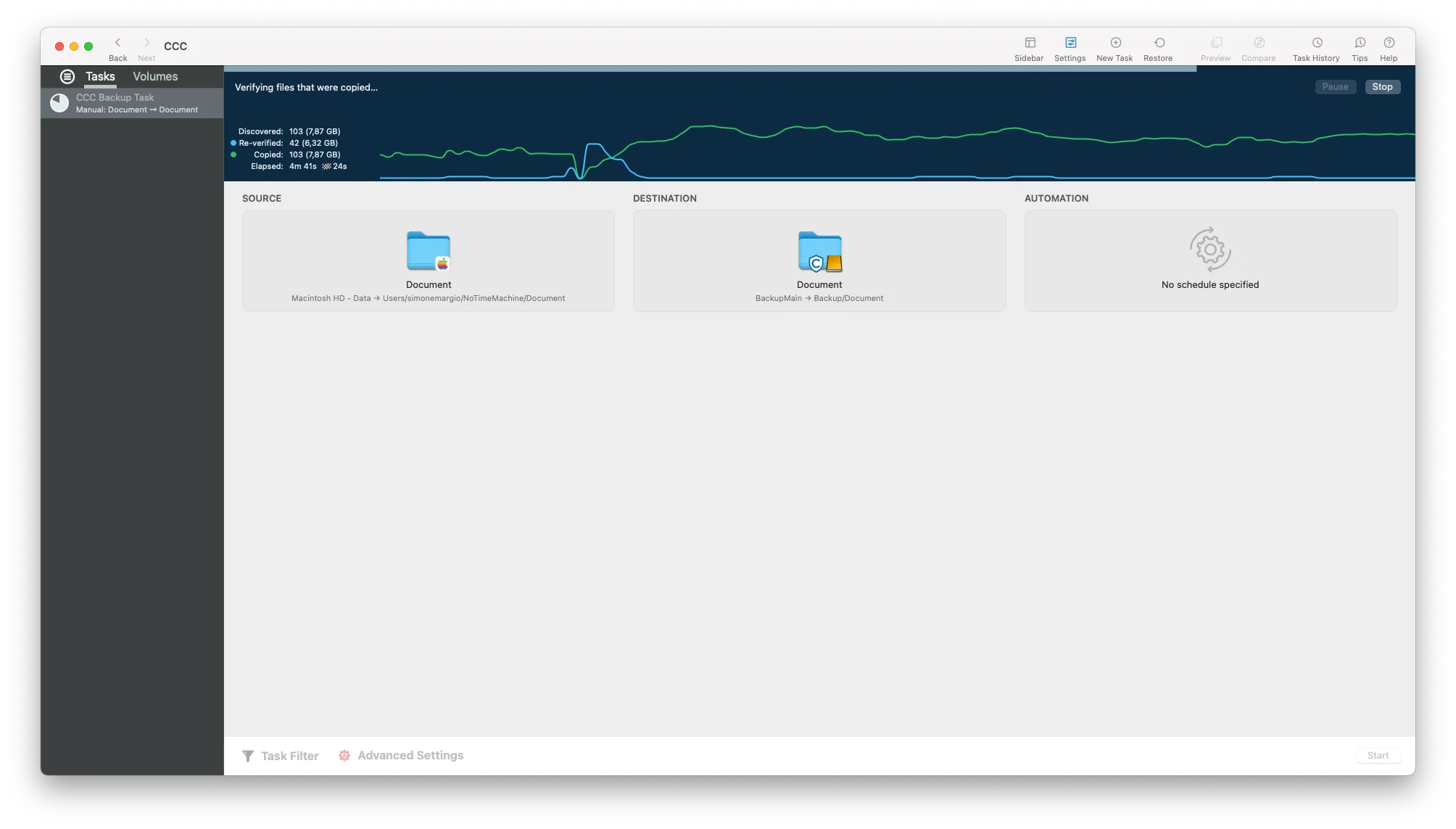
In this way, you have absolute certainty that each file has been copied correctly.
So it’s important not to rely on the human eye to verify the correctness of a copy but to use tools that allow you to verify the true equality between files.
Once all the files are efficiently indexed, where should they be saved?
Keeping in mind the 3-2-1 backup strategy:
- 3: you should have at least three identical copies of the data.
- 2: two of the three copies should be saved on different media.
- 1: one of the three copies should be saved in a completely different and distant place from the other two.
This week I focused on offsite data backup, which is the number 1 expressed above. This is the concept of offsite. If the house burns down, if all backup copies are stolen, if the disks fail, and all possible disasters lead to the inaccessibility of the 2 saved copies, the offsite copy represents your only chance of recovery.
The important premise is that thinking something like: “I copy everything to my Google Drive, Dropbox, OneDrive” is completely wrong!
Most cloud services are synchronization software, not backup software.
To explain it, let’s take this example. Suppose we have uploaded 500 files of our backup to the cloud. Of these 500 files, 1 is accidentally deleted/badly uploaded/modified/encrypted by ransomware or any other involuntary change, since the cloud is a synchronization process, then that “wrong” file will be synchronized on all devices you have access to.
In essence, that file is lost forever.
A backup, on the other hand, must guarantee 100% recovery of all files.
Having made this premise, let’s return to the initial question, where?
There are many services that offer a secure space for your files but since an offsite backup will be “forever”, the best choice is to use a service that you pay for based on the amount of data you upload.
Having 1TB of space for $5 a month can be appealing but if your backup doesn’t even reach 500GB it’s completely useless to pay for space that you’re not using at that moment.
Starting from this concept, my first choice was Amazon S3 Glacier Deep Archive storage class. The type of storage is the most suitable for the concept of offsite backup for its very low maintenance cost, many customizations to better structure the backup, and all the security behind a company that we know well.
But, there’s just one problem.
Ignoring the potential complexity that the user may face when calculating an estimate of the monthly price they will have to pay, there is no way to directly upload files to Glacier.
First, you have to create a general-purpose S3 bucket, and then move all the files to Glacier through a rule.
And this costs money.
To be precise, these are the costs due to Lifecycle Transition requests. So in addition to the cost of maintenance, access, download, and others, there is the cost of “transferring” files from S3 to Glacier.
But since we’re talking about an offsite backup, which will only be used in case we lose all other copies, all files necessarily have to go directly to Glacier, so we will pay for totally unnecessary transition cycles.
Because of this problem, I went back to evaluating an old service, Backblaze B2. The company was born with the sole purpose of securely saving user data and their B2 storage eliminates many price burdens that you would have with Amazon.
Less headache, fewer costs to consider, fewer customizations but more simplicity.
Unfortunately, unlike Amazon, they do not provide a way to estimate monthly costs. The only page provides a generic view of storage costs with Backblaze and other companies.
To get all the necessary information, you have to refer to the web page Pricing Organized by API Calls. Here we find all the costs for each type of operation and the cost for each GB of storage. Once all the data to be saved is taken, the calculation of an estimate is more or less quite simple.
But in the end, how much will the backup cost?
All the data that I consider fundamental comes to a total of 110GB. I made an estimate assuming to upload 200GB and pay all the costs for each type of operation requested by Backblaze. So we are talking about a limit estimate and quite pessimistic, but in this way a maximum spending ceiling is established.
In this case, the cost would be:
- Initial upload cost of all data: $ 1.70.
- Monthly maintenance cost: $ 1.2.
- Cost to download all 200GB together: $ 0.452.
To these estimates must then be added any currency exchange commissions and credit circuit payment fees, but in my case they do not affect the price so much.
So in the worst case, the annual cost in maintaining my hypothetical 200GB backup will be $ 14.4.
It is certainly another cost that adds to all the others, but if we consider that the backup is the last resort to recover data, then it is a cost worth paying.
In conclusion, the whole procedure of calculation, data structuring, backup cycle, and backup software management will be a topic for next blog post. There are many things to talk about and I didn’t want to go on too long in this weekly.
Remember, before creating new memories, think first about how to protect the ones you already have.